面对十万个为什么,计算机能否”谦虚谨慎”、准确回答?多轮口语对话中,计算机如何顺利接招,延续话题?顺着说、倒着说,首尾齐发,当突破人类极限时,高质量机器翻译呼之欲出……中国科学院自动化研究所研究者们提出三种“人机交互”新模型:任务型对话中,计算机也有了”自知之明”;人机多轮交互时,进一步强化语境记忆,提升了计算机口语理解能力;在生成文本时,首尾开弓的同步双向序列生成模型实现了质量与效率双赢。
1、任务型对话新框架:“谨慎”回答,“虚心”学习
人机对话技术旨在让机器像人一样自由对话与交流,是当前学术界和产业界的一大研究热点。任务型对话是人机对话的一种,在现实生活中应用最为广泛,可以通过对话实现某个特定任务。目前,任务型对话系统基本采用“一次设计、永久使用”的方式,默认机器可以回答所有问题,但是现实生活中却很容易遇到机器无法响应用户需求的情况。而此时,机器在不知道正确答案的前提下,还是会给出一个错误回答。
针对这个问题,自动化所自然语言处理团队博士生王唯康、副研究员张家俊、研究员宗成庆和出门问问公司合作提出了一种基于增量学习的任务型对话系统设计框架(Incremental Dialogue System),该框架让机器拥有了“自知之明”,在答案不确定时会主动向人工求助,并从人工回答中不断学习和完善。
该框架可以度量当前系统回复的不确定性程度。当系统有较高置信度时,机器给出回复;反之,由人工介入对话过程。同时,人工介入所产生的数据会反馈到模型中扩展系统的候选回复集合并优化模型参数,使得系统上线后还能不断地学习以适应未考虑到的情形。在模型的不确定性程度较低时人工会介入对话,这一特性使得系统会在出现差错之前咨询人工的建议,所以会极大程度地降低给出不合理回复带来的风险。另外,不确定性估计模块还能让系统以更少的数据量达到更好的性能。
相关研究成果发表于自然语言处理顶级学术会议ACL-2019(Weikang Wang, Jiajun Zhang, Qian Li, Mei-Yuh Hwang, ChengqingZong and Zhifei Li. Incremental Learning from Scratch for Task-Oriented Dialogue Systems. ACL-2019)。
2、多任务学习新模型:多轮交互,沟通无阻
近年来,在学术界评测与工业界需求的推动下,任务型对话系统中的口语理解逐渐成为一个活跃的研究领域,并取得相当的进展。目前的口语理解大多对单轮话语进行解析,但是对话通常是人机多轮交互。已有些研究表明,对话历史对当前用户话语的解析有重要作用,但这些研究关于对话历史的建模还很初步,没有充分挖掘对话历史信息。
鉴于此,自动化所自然语言处理团队首先定义了对话逻辑顺序推断(DLI)这一辅助任务,然后通过将DLI与SLU共享记忆编码与记忆检索模块,在多任务学习框架下进行联合优化,进而强化语境记忆表示,提升多轮口语理解的性能。
DLI任务不需要额外的标注数据且在模型解码阶段不占用额外的计算时间。另外,DLI任务对于多任务学习中的损失权重较为鲁棒。研究者们在两个数据集上的实验表明:多种多轮口语理解模型都能够从该研究提出的方法中得到提升,并且在语义槽识别任务上提升显著。
相关研究成果发表于自然语言处理顶级学术会议ACL-2019(He Bai, Yu Zhou, Jiajun Zhang and Chengqing Zong. Consolidation for Contextual Spoken Language Understanding with Dialogue Logistic Inference. ACL-2019)。
3、同步双向序列生成模型:首尾开弓,质效双赢
正常人说话都是从第一个词到最后一个词顺着说,极少数人可以从最后一个词到第一个词倒着说。不管是顺着说还是倒着说,计算机都很容易实现。最近,自动化所自然语言处理团队构建了一种同步双向序列生成模型(SBSG),不仅刷新了计算机“说话”的极限,也挑战了人类说话的极限:同时顺着说和倒着说,到中间点结束。该算法可应用于机器翻译和自动摘要,不仅显著提升了文本生成的效率,还改善了生成文本的质量。
当前,基于编码器-解码器结构的序列生成模型广泛应用于自然语言生成任务,例如神经机器翻译、摘要生成等。这种框架通常采用自回归的方式,即从左到右依次生成目标语言单词,该方式有两个缺点:(1)当输出句子变长时,这种自回归解码过程非常耗时,其解码时间和生成序列的长度成线性关系;(2)解码时只能依赖已经生成的历史序列,缺乏未来信息的指导。
自动化所提出的同步双向序列生成模型(SBSG)采用了从目标序列的两端往中间的生成方式,每个时刻可以生成两个单词,相对于传统序列生成模型而言,理论上可以减少近一半的解码时间。其次,SBSG模型使用了一个交互双向注意力网络来实现从左到右解码(L2R)和从右到左解码(R2L)之间信息的相互利用,即一种解码模式可以利用另一种解码模式生成的序列来指导当前的解码。不同于生成质量出现显著下降的非自回归模型,SBSG模型相比于当前最优的自回归的Transformer模型在序列产生质量和解码速度上都得到了显著提升。
相关研究成果发表于人工智能顶级学术会议IJCAI-2019(Long Zhou, Jiajun Zhang, ChengqingZong and Heng Yu. Sequence Generation: From Both Sides to the Middle. IJCAI-2019)。
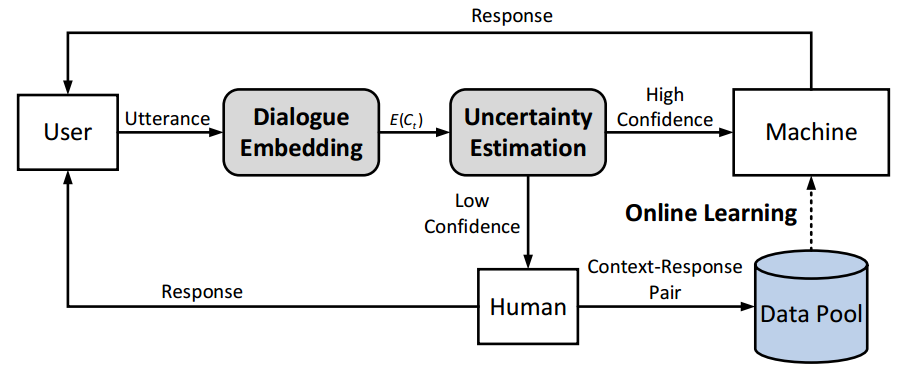
基于增量学习的对话系统设计的框架图
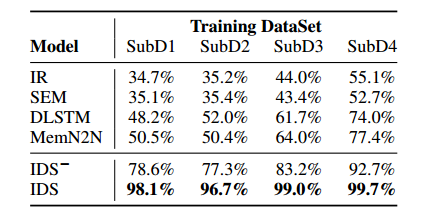
不同模型的平均正确率
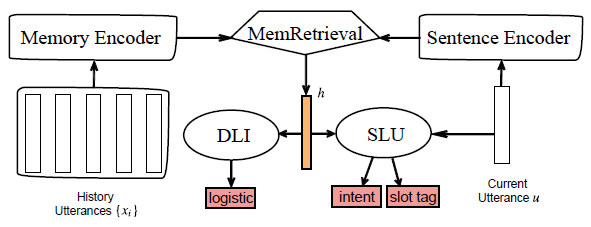
DLI与SLU多任务学习模型框架
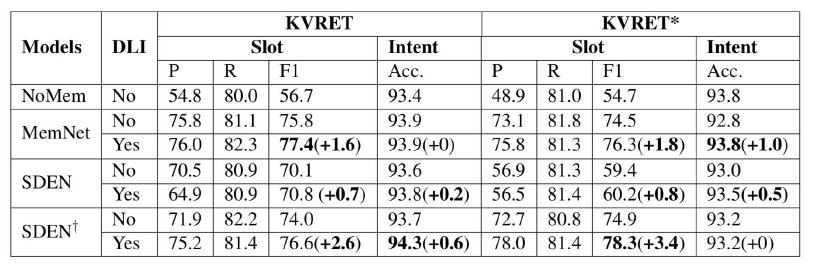
实验结果
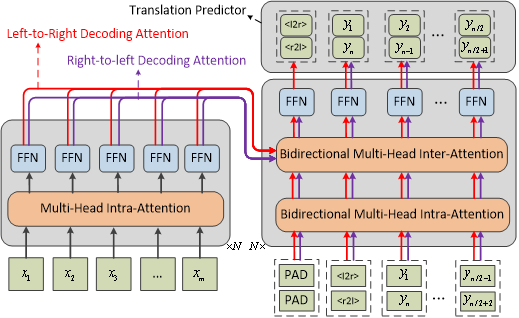
模型结构
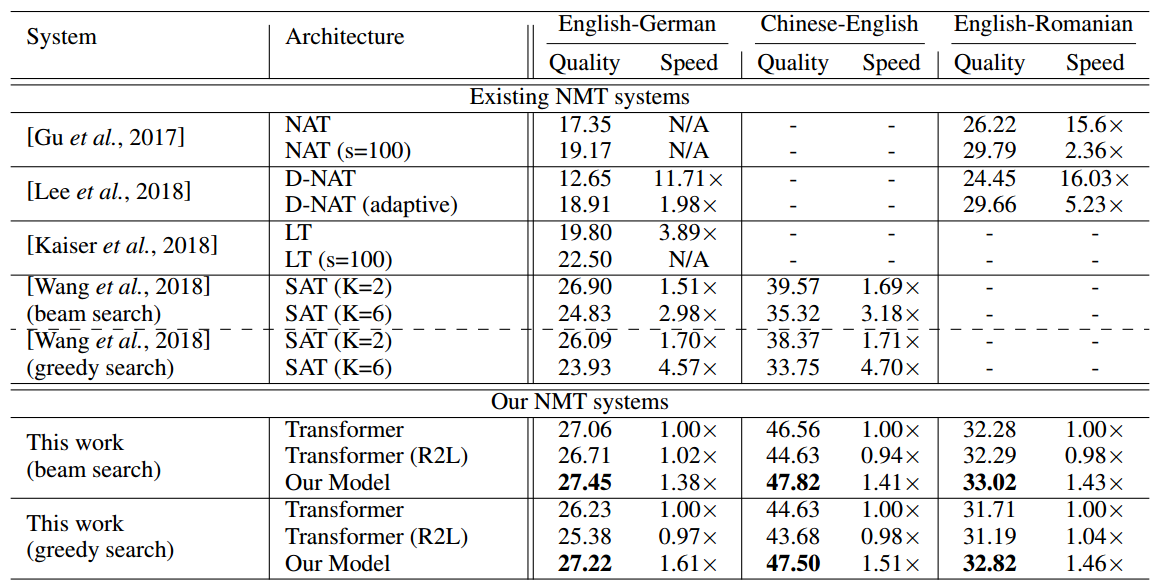
机器翻译实验结果
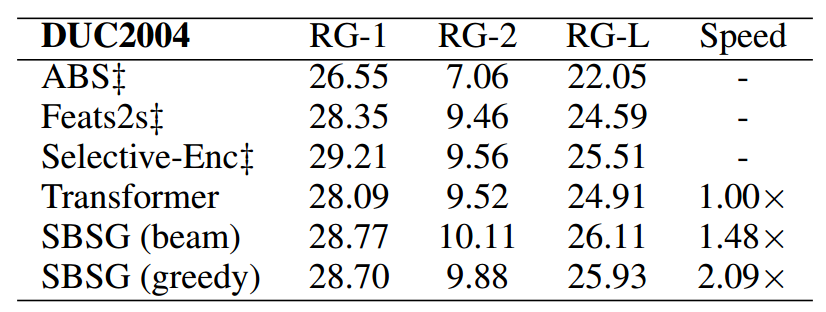
文本摘要实验结果

